SQL - Jupyter Notebook을 활용한 데이터 분석
- 그동안 배운 SQL을 jupyter notebook과 연결하여 여러가지 해보려고 한다.
- 나는 '컴퓨터공학'을 전공한 전공자도 아니고, 구글 열심히 찾아가면서 실행이 가능하게끔 만드는 것이 목표이다.
- 혹시나 전문적인 지식을 원하는 사람이 링크를 잘못 타고 이곳으로 왔다면,,, 확실한 전문 지식은 다른곳에서 구하길 바란다.
1. 패키지 설치
- 먼저 패키지 설치부터 해보자.(Anaconda, jupyter notebook, VScode는 설치되어있어야 한다.)
// Anaconda Prompt에서 패키지를 설치한다.
pip install cx_Oracle
pip install ipython-sql

2. VScode에 Oracle 연결
// sql을 로드한다.
%reload_ext sql// 사용할 라이브러리를 가져온다.
import cx_Oracle
import pandas as pd
import matplotlib.pyplot as plt
import folium
// cx_Oracle 라이브러리를 사용해서 sql과 연결한다.
// userid, password 부분은 처음 sql에 설정한대로 적어준면 된다.
con = cx_Oracle.connect('userid/password@localhost') // oracle 접속
// oracle에서 실행시킬 query문 작성
query = """
SELECT *
FROM 테이블명
"""
// con(connect)으로 접속하여 query를 날린 후 출력되는 값을
// read_sql로 불러와서 df에 DataFrame형태로 저장
df = pd.read_sql(query, con=con)
df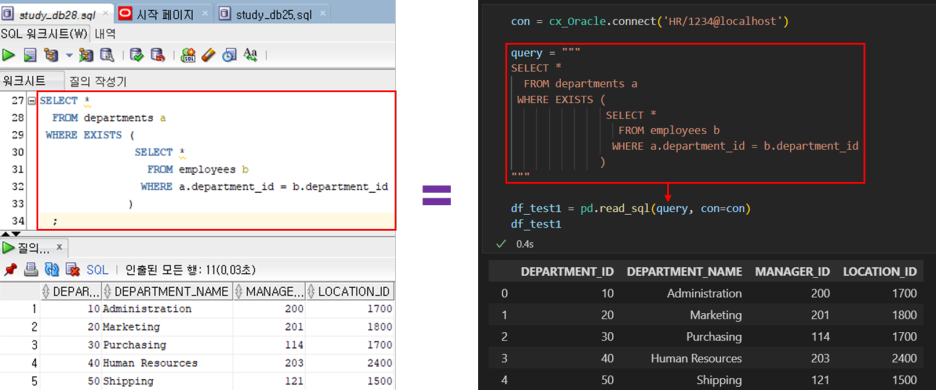
- 그동안 SQL에서 작성했던 것과 동일하게 VScode의 jupyter notebook에서 사용 가능하다.
- SQL문 실행 결과를, pandas의 DataFrame형태로 출력한다.

- 25일차 실습내용도 잘 작동한다.
query = """
SELECT *
FROM cctv
"""
df_test3 = pd.read_sql(query, con=con)
df_test3.head(3)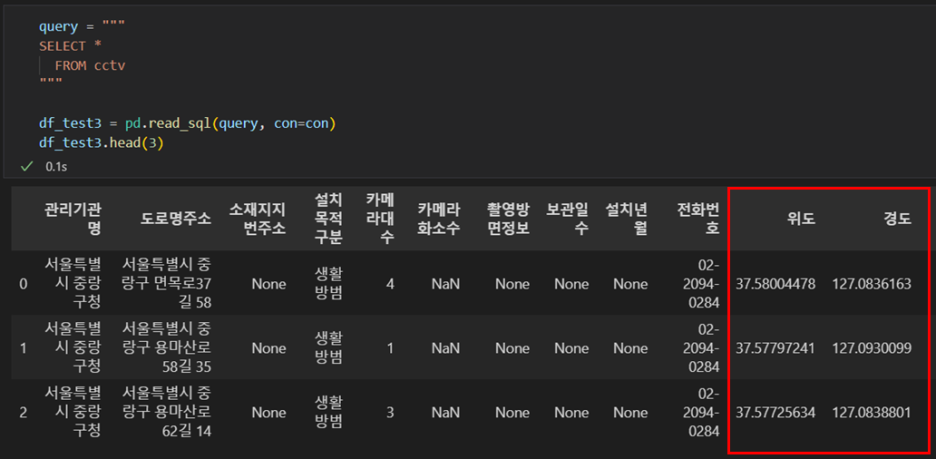
- 전체 데이터를 다시 확인해본다.
- 위도와 경도가 표시되어있다. 이 값을 이용해서 지도에 cctv 설치 현황을 표시해보려고 한다.
# 지역별 설치 현황
query = """
SELECT TRIM(
REPLACE(REPLACE(REPLACE(관리기관명, '서울특별시',''), '구청','구'), '경찰서','구')
) AS 지역
, SUM(카메라대수) AS 전체카메라설치수
, AVG(위도) AS 위도
, AVG(경도) AS 경도
FROM cctv
GROUP BY
TRIM(
REPLACE(REPLACE(REPLACE(관리기관명, '서울특별시',''), '구청','구'), '경찰서','구')
)
"""
df_test4 = pd.read_sql(query, con=con)
print(len(df_test4))
df_test4.head(3)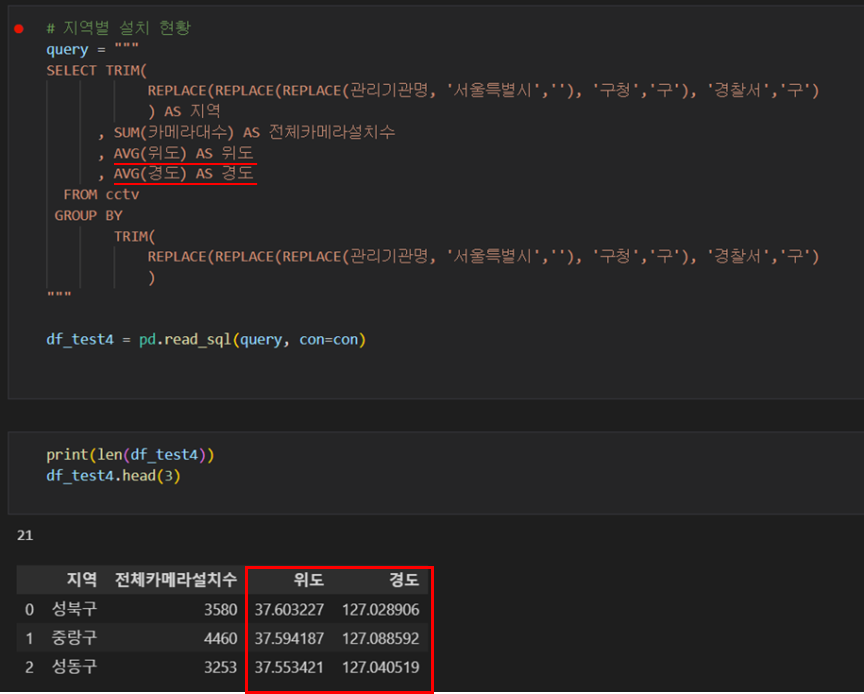
- 지역별 cctv 설치 현황 데이터를 가져온다.
- 지역의 위도, 경도는 전체 cctv 위도, 경도 위치의 평균값으로 계산했다.
3. matplotlib을 이용한 시각화
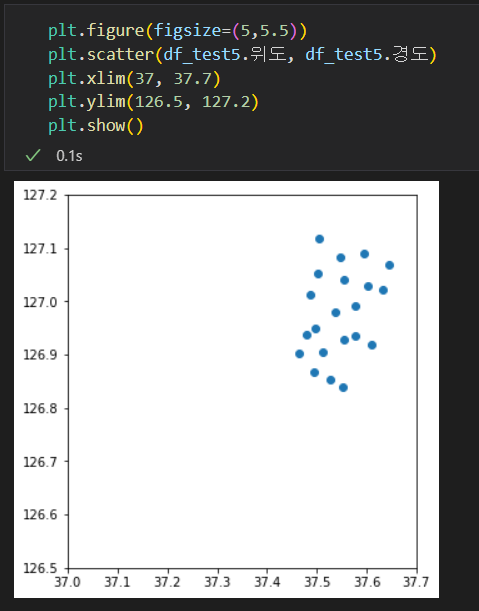
- matplotlib은 데이터 시각화 라이브러리다. 이를 이용해서 데이터를 시각화한다.
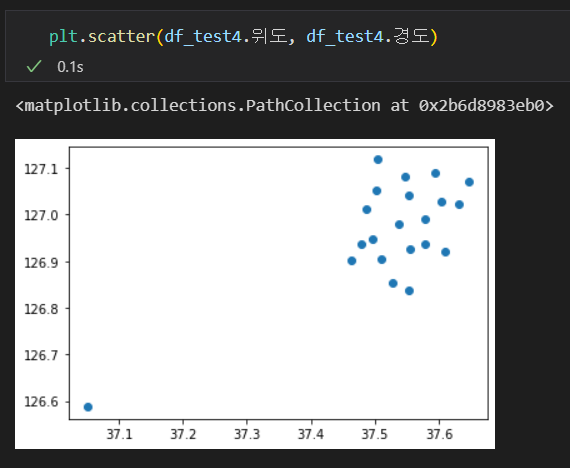
- 구 단위로 그룹화한 위도, 경도의 위치를 점으로 표시하면 위와 같다.
- 이상하게 벗어나있는 점을 확인할 수 있다.
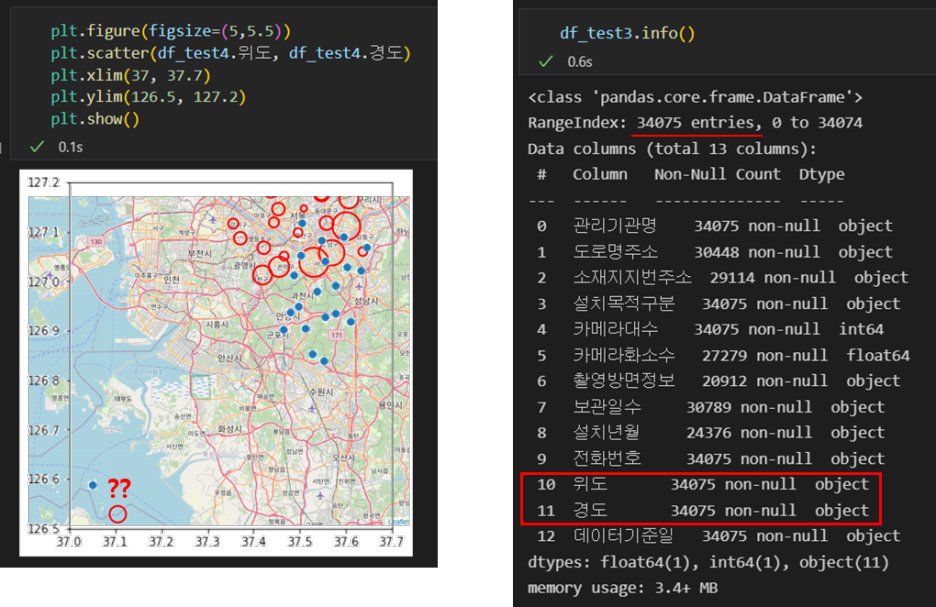
- 왼쪽 그림은 plt에 지도를 겹친 이미지이다. 각 이미지가 왜곡이 있긴 하지만, 너무 동떨어진 곳에 표시되어있다.
- 전체데이터(df_test3)에서도 따로 null값은 없다. 무슨값인지 찾아보자.
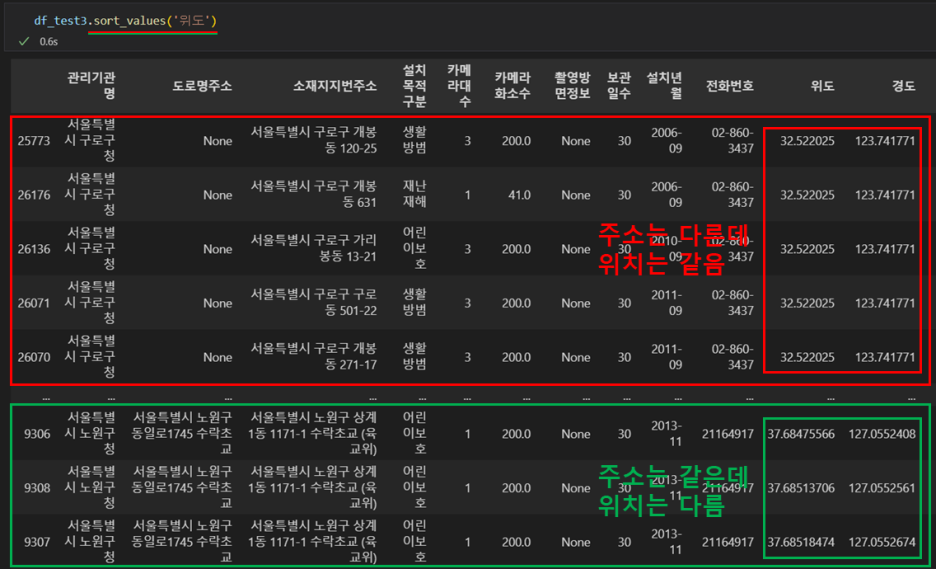
- 주소가 같아도 cctv 설치 위치가 다를수는 있다(초록색)
- 하지만, 주소가 다른데 cctv설치 위치가 같다는 것은 값이 잘못 들어갔거나, 위치를 알 수 없어서 임의로 특이값을 넣어둔 것으로 보인다.(빨간색)
- 이상치이기 때문에 삭제한다.
4. 이상치 삭제
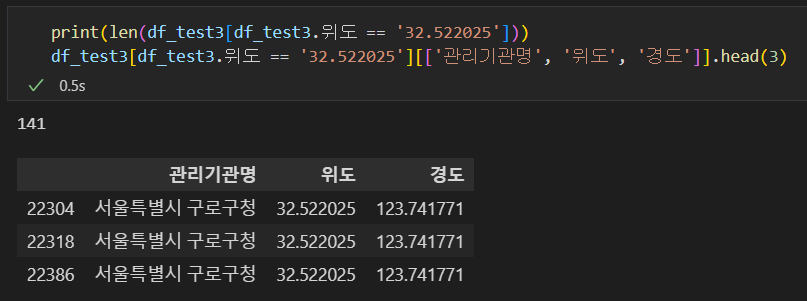
- 총 141개의 데이터가 같은 위도값을 갖고있으며, 모두 구로구에 해당한다.
# 지역별 설치 현황
query = """
SELECT TRIM(
REPLACE(REPLACE(REPLACE(관리기관명, '서울특별시',''), '구청','구'), '경찰서','구')
) AS 지역
, SUM(카메라대수) AS 전체카메라설치수
, AVG(위도) AS 위도
, AVG(경도) AS 경도
FROM cctv
WHERE 위도 NOT IN 32.522025
GROUP BY
TRIM(
REPLACE(REPLACE(REPLACE(관리기관명, '서울특별시',''), '구청','구'), '경찰서','구')
)
"""
df_test5 = pd.read_sql(query, con=con)
print(df_test5[df_test5.지역 == '구로구'])
print(df_test4[df_test4.지역 == '구로구'])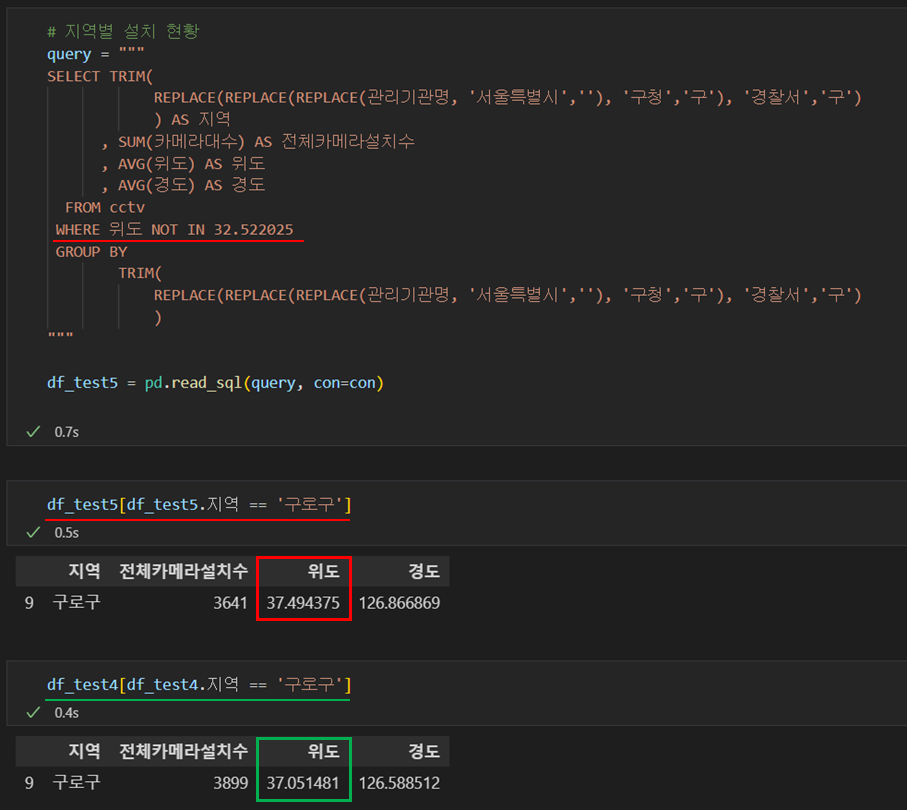
- cctv의 위도가 같은 값을 제거하고, 다시 데이터를 불러온다.
- 결과값을 보면 위치가 달라지고, 전체 카메라 설치 수도 작아졌다.
- (카메라 수가 정확하게 141이 차이나지는 않는다. 기관명때문에 더 적게 검색되었던 것 같다.)
- 수정이 잘 되었다.
5. folium을 이용한 시각화
- folium은 지도 라이브러리이다. 이를 이용해서 지도위에 데이터를 표시한다.
cctv_num = 0
latitude = df_test4['위도'][cctv_num]
longitude = df_test4['경도'][cctv_num]
map1 = folium.Map(location=[latitude, longitude], zoom_start=10)
map1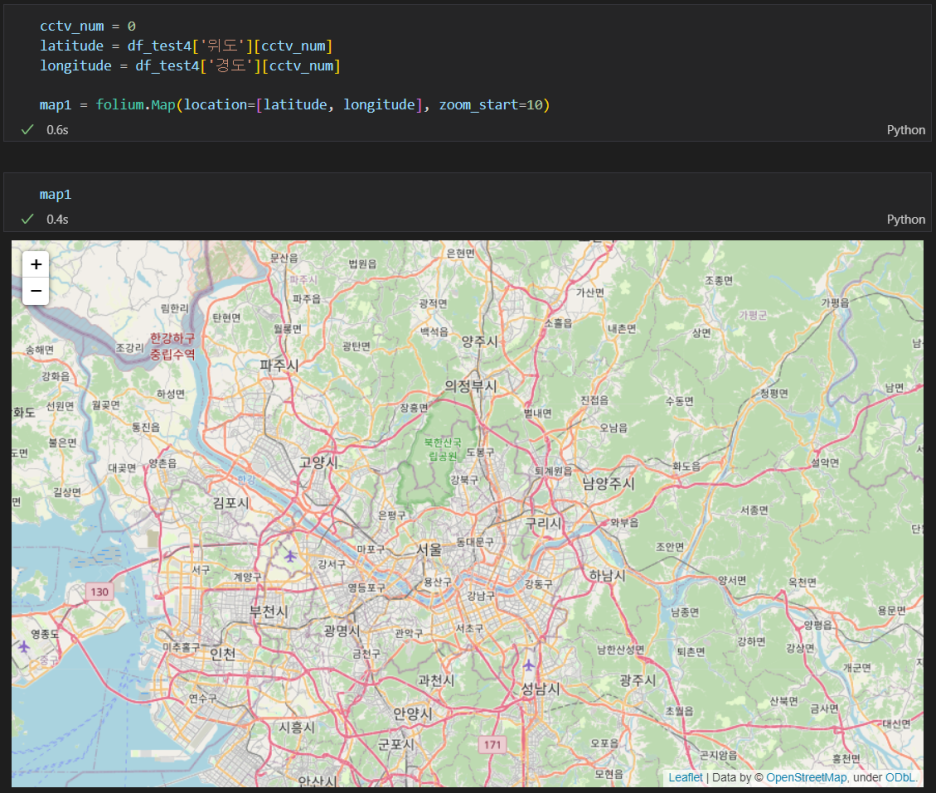
- cctv를 표시할 초기 map 이미지를 셋팅한다.
- 기준위치(위도, 경도)와 zoom으로 얼마나 크게 표현할 것인지 값을 넣어준다.
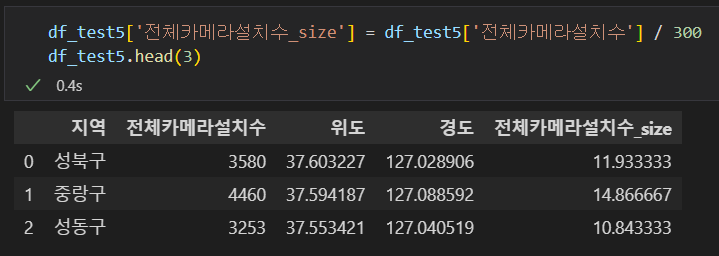
- 시각화 부분에서 전체 카메라 설치 수만큼 원의 크기를 그릴거라, 새로운 컬럼으로 만들어준다.
- 크기는 10~15정도가 적당해서 300으로 나눈 값을 사용한다.
for i in range(len(df_test5)):
cctv_num = i
latitude = df_test5['위도'][cctv_num]
longitude = df_test5['경도'][cctv_num]
map_marked1 = folium.CircleMarker([latitude, longitude]
, radius= df_test5['전체카메라설치수_size'][cctv_num]
, color = 'red'
,
)
map_marked1.add_to(map1)
map1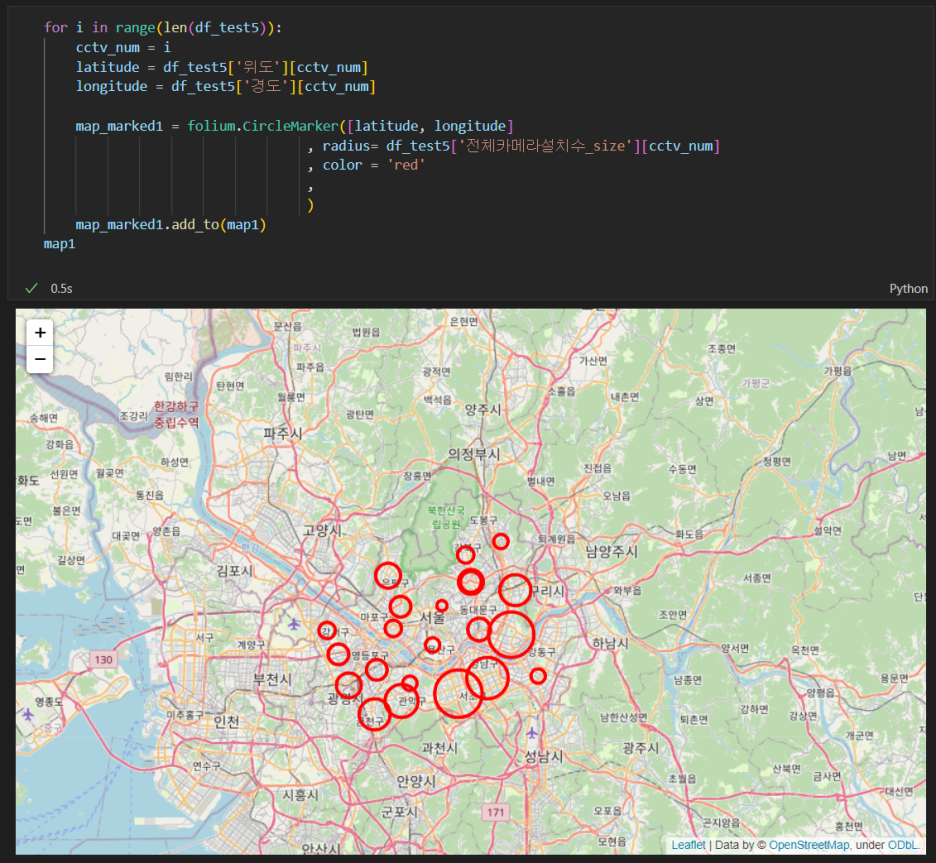
- for문을 돌면서 구별로 cctv 위도, 경도의 평균 위치를 가져와서 CircleMarker로 표시해준다.
- 각각의 원 size는 카메라 설치 수에 따라, 많을수록 크게 그려지고, 적을수록 작게 그려진다.
- 종로, 용산, 송파, 노원구에는 cctv가 조금 설치되어있다.
- 강남, 서초, 광진구쪽은 cctv가 많이 설치되어있다.
6. 결론
- 데이터를 보고, '강남구에 cctv가 많으니까 치안이 좋을 것이다'라고 생각할 수 있다.
- 반대로, '강남구 치안이 좋지 않기 때문에 cctv가 많이 설치되었다'라고 생각할 수도 있다.
- 인과관계를 분석하는 것은 또다른 영역이기 때문에, 추가적인 공부가 필요하다.
'클래스 리뷰 > 22.05 빡공단 SQL 강의' 카테고리의 다른 글
| 빡공단 22기 도전기 - 마지막 실습 (30일차) (0) | 2023.01.09 |
|---|---|
| 빡공단 22기 도전기 - 4주차 미션 (0) | 2023.01.08 |
| 빡공단 22기 도전기 - SQL 속도와 성능을 고려한 코드작성 (29일차) (1) | 2022.12.07 |
| 빡공단 22기 도전기 - SQL WHERE 서브쿼리 (28일차) (2) | 2022.12.07 |
| 빡공단 22기 도전기 - SQL FROM 서브쿼리 (27일차) (0) | 2022.12.07 |




댓글