3주차 요약
3주차는 지도학습(Supervised Learning)의 한 부분인 분류(Classification)에 대해 공부했다.
4가지 모델(Linear Classifier, Logistic Regression, Decision Tree, Random Forest)에 대한 이론 설명과 실습으로 구성되었다.
(이론 정리부터 하고 실습은 추후에 첨부할 예정이다.)
분류(Classification) 모델
1). Linear Classifier(선형 분류)
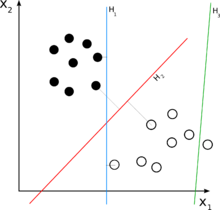
Linear Classifier는 하나의 선형 식으로 데이터를 나누어 구분하는 방법이다.
위 그림(from wikipedia)과 같이 검은색 점과 흰색 점을 구분하려고 할 때, 파란색 선(H1)과 빨간색 선(H2)이 데이터를 잘 구분하고 있다. 그리고 그 중에서도 빨간색 선이 데이터를 더 보기좋게 구분하는 것을 직관적으로 알 수 있다.
선은 y=w1*x1 + w2*x2 +b로 표현할 수 있으며, y, x1, x2는 주어진 데이터이기 때문에, w1, w2, b를 찾는 문제가 된다.
2). Logistic Regression(로지스틱 회귀)

Logistic Regrssion은 대표적인 이진 분류 모델로, '맞냐, 틀리냐', '0이냐, 1이냐' 와 같이 구분하는 문제이다.
왼쪽 그림의 Linear Regression은 회귀(Regression) 부분에서 다루겠지만, 선형식으로 값을 예측하는 방법이다.
이 선형식을 Sigmoid Function을 이용하여 변형시키면, 0 혹은 1의 값을 갖는 함수로 바꿀 수 있다.
따라서, 데이터 X가 주어졌을 때 y가 0 혹은 1 중 어디에 확률적으로 가까운지 계산할 수 있게 된다.
3). Decision Tree

분류(Classification) 부분에서 소개하지만,
Decision Tree 중 CART(Classification and Regression Tree)모델은 분류, 회귀 둘다 사용 가능하다.
그림과 같이 어느 분기에서 어떤 기준으로 분류되었는지 확인 가능하기 때문에 결과에 대한 설명이 가능하다.
분기가 계산되는 기준은 몇가지가 있는데,
간단하게 써보면 가장 분류가 잘 되는 지점을 계산하여 나누고, 또 계산해서 나누고 하는 식으로 만들어진다.
직관적이고 계산하기 편하지만, *Overfitting 되기 쉽다.
(*Overfitting(학습 데이터에만 과하게 적합한 모델이 되는 현상))
4). Random Forest
Decision Tree의 Overfitting 문제를 완화할 수 있는 방법으로,
Tree 모델을 여러개 만들어서 평균적으로 사용하는 것이다.
이렇게 하면 학습모델이 여러개 생기는 것과 같은 효과를 갖기 때문에, 하나의 학습모델에 치중하지 않고 데이터를 전반적으로 고려한 모델이 만들어지게 된다.
Tree 모델을 여러개 만드는 방법은 2가지가 있다
- Bagging : 모집단에서 샘플을 랜덤하게 뽑아 Tree 모델을 여러개 만든다.
- Random Subspace Method : 학습에 사용하는 feature를 선택적으로 뽑아서 Tree 모델을 여러개 만든다.
분류모델 정리는 여기까지!
※ 이 글은 내일배움카드를 이용한 국비지원교육인 K-Digital 기초역량훈련 딥러닝 강의 학습일지입니다.
※ 강의내용을 그대로 가져온 것이 아닌, 학습 과정을 기반으로 개인적으로 풀어 쓴 학습일지입니다.
'클래스 리뷰 > 22.12 K-Digital 기초역량훈련 딥러닝 강의' 카테고리의 다른 글
| [패스트캠퍼스] 딥러닝 강의 - 5주차 학습일지 - 클러스터링 모델 정리 (0) | 2023.02.08 |
|---|---|
| [패스트캠퍼스] 딥러닝 강의 - 4주차 학습일지 - 회귀 모델 정리 (0) | 2023.02.03 |
| [패스트캠퍼스] 딥러닝 강의 - 2주차 학습일지 (0) | 2023.01.15 |
| [패스트캠퍼스] 딥러닝 강의 - 1주차 학습일지 (0) | 2023.01.08 |
| [패스트캠퍼스] 딥러닝 강의 - 신청 (0) | 2023.01.03 |




댓글