 pandas로 논문 형식의 table 작성하기
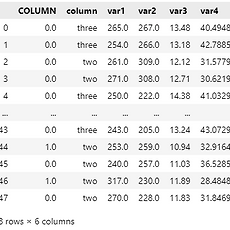
1. Data 형태 - COLUMN은 0, 1로 구분되어 있다. - column은 one, two, three로 구분되어 있다. - 변수는 4가지가 있다.(Variable 1~4) - COLUMN, column을 이용하여 멀티컬럼(Multicolumn)을 만들고, 변수의 평균, 편차를 보고자 한다. 2. 평균 편차 계산 variables = ['var1', 'var2', 'var3', 'var4'] Table_mean = (Table.groupby(['COLUMN', 'column'])[variables].mean().T).round(2) Table_std = (Table.groupby(['COLUMN', 'column'])[variables].std().T).round(2) col_0 = Table_m..
2023. 1. 2.
pandas로 논문 형식의 table 작성하기
1. Data 형태 - COLUMN은 0, 1로 구분되어 있다. - column은 one, two, three로 구분되어 있다. - 변수는 4가지가 있다.(Variable 1~4) - COLUMN, column을 이용하여 멀티컬럼(Multicolumn)을 만들고, 변수의 평균, 편차를 보고자 한다. 2. 평균 편차 계산 variables = ['var1', 'var2', 'var3', 'var4'] Table_mean = (Table.groupby(['COLUMN', 'column'])[variables].mean().T).round(2) Table_std = (Table.groupby(['COLUMN', 'column'])[variables].std().T).round(2) col_0 = Table_m..
2023. 1. 2.









