1. 크롤링 과정 간단정리
1). 개발자 도구
- elements tap : 어떤 tag와 어떤 속성을 갖는지 표시
- network tap :
- clear : log 지움
- preserve log : log 기록
- browser에서 server에 자료를 요청하고, 업로드되는 것을 볼 수 있음
- 이미지의 경우 개별적으로 업로드 됨
- 댓글의 경우도 API를 이용하여 개별적으로 업로드 됨
2). HTTP Mathod : HTML 문서 등의 리소스를 전송하는 프로토콜
- HTML(Hyper Text Markpu Language) : 웹사이트를 생성하기 위한 언어로 문서와 문서가 링크로 연결되어 있고, 태그를 사용하는 언어
- 리소스 요청 : 클라이언트 → 서버(Get, Post 등)
- 리소스 응답 : 클라이언트 ← 서버
- 리소스 요청 방법 2가지
-- Get 요청 : 데이터를 URL에 포함하여 전달(주로 리소스 요청에 사용)
-- Post 요청 : 데이터를 Form data에 포함하여 전달(주로 로그인에 사용)
3). HTML Elements
- Tag : HTML에서 코드의 기능을 설명 혹은 구현하는 것
- HTML문서의 기본 블럭 : <Tag명 속성1="속성값1" 속성2="속성값2">Value</Tag명>
4). requests 모듈 사용하기(HTTP 통신 자동화)
- python library 중 하나로 HTTP 통신에 사용
5). Open API를 활용하여 json 데이터 추출하기(공공데이터 API)
- 공공데이터 포털 Open API 사용하기
- Open API 요청
- key값
6). beautifulsoup 모듈 사용하여 HTML 파싱하기(parshing)
7). id, class 속성을 이용하여 원하는 값 추출하기
8). CSS를 이용하여 원하는 값 추출하기
9). 사이트에 로그인하여 데이터 크롤링하기
10). selenium 모듈로 웹사이트 크롤링하기
2. CGV 리뷰 크롤링 실습
이전에 배웠던 웹크롤링을 이용하여, '영화 리뷰'를 검색해보고자 한다.
영화계의 큰손 CGV에는 리뷰가 많고 크롤링도 허용해두어서 법적인 문제는 없는 듯 하다.
(/robots.txt 로 확인해봤다..)

1). 영화 제목 입력
먼저 리뷰를 보고자 하는 영화를 입력해야 한다.

2). 홈페이지 접속
chrome_dirver를 이용하여 홈페이지를 연다.
chrome_driver = '/Users/user/Downloads/chromedriver'
driver = webdriver.Chrome(chrome_driver)
driver.get("https://www.cgv.co.kr/")
3). 영화 검색
위(1).)에서 입력받은 영화 제목을 검색창에 대입시켜준다.
driver.find_element_by_id("header_keyword").send_keys(movie) # 영화제목 입력
driver.find_element_by_id("header_keyword").send_keys('\n') # 검색 후 '엔터'엔터까지 입력했기 때문에 바로 페이지가 이동된다.
4). 여러 영화 중 선택
제목을 완전 구체적으로 쓰지 않는 한 입력값이 포함된 영화들이 전부 색인된다. '어벤져스'와 같이 시리즈물 역시 여러 시리즈가 색인된다. 영화가 하나만 검색되면 상관없지만, 여러 영화가 검색되는 경우를 고려하여 가장 앞에 있는 영화를 검색하고자 한다. 시리즈 영화도 '어벤져스', '해리포터' 검색 결과가 다르고 크롤링 할 때 위치도 다르다.
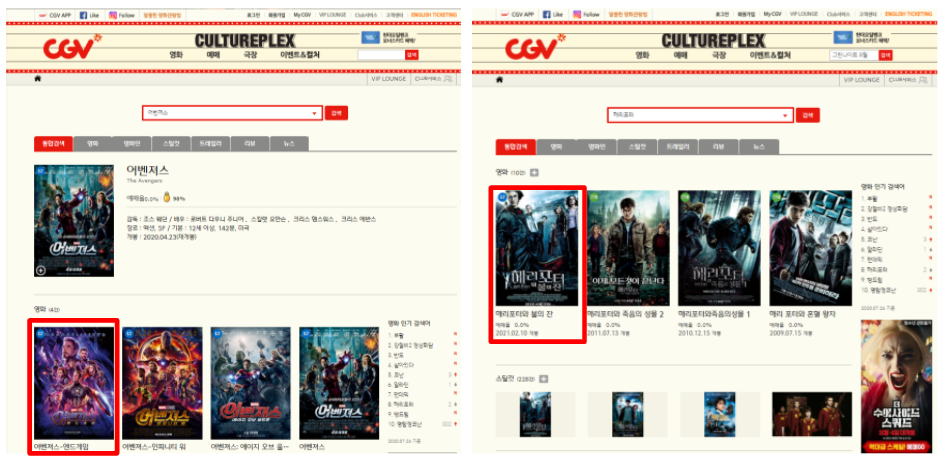
따라서 XPath를 검색하고, XPath 주소가 작은 것부터 확인하고 페이지에 들어갈 수 있도록 조건문을 사용하였다.
# 첫번째 영화의 위치를 찾은 결과 아래와 같이 두 가지로 XPath주소가 나온다.
if driver.find_elements_by_xpath('//*[@id="contents"]/div/div[3]'):
WebDriverWait(driver, 5).until(EC.element_to_be_clickable((By.XPATH, '/html/body/div[2]/div[3]/div[2]/div/div[3]/div[1]/div/div[1]/ul/li[1]/div[2]/a/strong'))).click()
else:
WebDriverWait(driver, 5).until(EC.element_to_be_clickable((By.XPATH, '/html/body/div[2]/div[3]/div[2]/div/div[2]/div[1]/div/div[1]/ul/li[1]/div[2]/a/strong'))).click()
5). 검색된 영화의 리뷰 6개 가져오기
첫번째 영화의 페이지에 접속하면 리뷰 6개가 나온다. 리뷰 6개의 '날짜', '리뷰'를 가져와서 list에 담는 코드를 만들었다.

for j in range(1, 6):
# 한 Page에 6개의 날짜 가져오기
review_date = driver.find_element_by_xpath('/html/body/div[2]/div[3]/div[2]/div/div[4]/div[1]/div[6]/div[3]/ul/li[{0}]/div[2]/ul/li[2]/span[1]'.format(j)).text
# 한 Page에 6개의 리뷰 가져오기
review_list = driver.find_element_by_xpath('/html/body/div[2]/div[3]/div[2]/div/div[4]/div[1]/div[6]/div[3]/ul/li[{0}]/div[3]'.format(j)).text
# 날짜, 리뷰 list에 담기
reveiw_dates.append(review_date)
reveiw_lists.append(review_list)
6). 리뷰 페이지 1 ~ 10
한 페이지 안에 리뷰 페이지가 10개가 있다. 반복문으로 1~10까지 반복하여 크롤링 한다. 다음 10개로 넘어가면 위치가 바뀌기 때문에 주소도 바뀐다. 조건문으로 나눠서 어떤 상황이든 첫번째 리뷰 페이지부터 가져올 수 있도록 작성한다.

if driver.find_elements_by_xpath('/html/body/div[2]/div[3]/div[2]/div/div[4]/div[1]/div[7]/ul/li[1]/a'):
WebDriverWait(driver, 5).until(EC.element_to_be_clickable((By.XPATH, "/html/body/div[2]/div[3]/div[2]/div/div[4]/div[1]/div[7]/ul/li[{0}]/a".format(i)))).click()
else:
WebDriverWait(driver, 5).until(EC.element_to_be_clickable((By.XPATH, "/html/body/div[2]/div[3]/div[2]/div/div[4]/div[1]/div[7]/ul/li[{0}+2]/a".format(i)))).click()
7). 다음 10개 클릭
1~10 리뷰 페이지 검색이 끝나면 '다음 10개' 버튼을 눌러서 다음페이지로 넘어가야 한다. 위와 같은 방법으로 XPath 주소를 잘 찾아서 대입하면 완성이다.
8). 느낀점
XPath 주소는 '지역주소', '전역주소'?? 번갈아가면서 썼는데, 다음에는 더 깔끔하게 만들 수 있을거같다. 크롤링은 자주 사용하는 함수만 잘 기억하고, 홈페이지에서 주소만 잘 가져오면 어렵지 않게 만들 수 있을것 같다.
'클래스 리뷰 > 21.06 K-Digital Training AI 데이터 사이언티스트 과' 카테고리의 다른 글
| 데이터베이스 이론 (2) | 2023.03.05 |
|---|---|
| Numpy, Pandas, Seaborn (0) | 2023.02.22 |
| python 기초 문법 (1) | 2023.02.21 |
| [K-Digital Training] 패스트캠퍼스 AI 기반 데이터 사이언티스트 과정 - 신청에서 합격까지 (0) | 2023.01.12 |


댓글